

在这篇文章中,我将详细分享我最近参加的一次Google面试经历。这是一场让我印象深刻的技术面试,不仅让我面对了两个编程挑战,还让我在实际对话中展现了自己的沟通能力和问题解决能力。通过重现面试中的真实对话,希望为大家提供一个更加贴近实际的面试体验。
In this blog post, I will share my recent experience during a Google interview. It was an intense technical interview where I faced two coding challenges. Along with solving the problems, the interview involved detailed discussions with the interviewer, who guided me through clarifying the requirements and improving my solutions. I’ll recreate the exact conversations and explain the thought process behind each solution to give a realistic sense of the interview.
引言
这次面试主要包含两个编程题,侧重于数据结构和算法应用。每个问题不仅要求给出正确的解决方案,还需要考虑边界情况并优化代码效率。同时,面试过程中的沟通也非常重要。在这个过程中,面试官通过与我互动,不断引导我澄清问题和优化思路。
Introduction
This Google interview primarily focused on two coding challenges. Both questions required me to apply data structures and algorithms efficiently, while also considering edge cases and ensuring the optimal performance of my code. Throughout the interview, communication was a key factor, as the interviewer encouraged me to clarify my approach and reasoning.
第一个问题: Swipe Path 预测
面试的第一个问题是关于Swipe Path的预测问题。
面试官问题原文: "When someone drags their finger across a phone's keyboard, we can record the letters they intersected, creating a swype path. Given a swype path and a list of words, write a function to guess what the user is trying to type."
输入:
- 一个滑动路径字符串,例如
"bjiojbfdsaq" - 一个单词列表,例如
["boba", "tea", "apple"]
输出:
- 返回最可能输入的单词,例如
"boba"
在听到问题描述后,我首先确认了一些假设和边界条件。
我:
“Are we assuming all letters in the input are lowercase? Also, do we need to consider non-alphabetic characters, or will the input always be valid English words?”
面试官:
“Yes, you can assume the input will only contain lowercase English letters, and no need to handle non-alphabetic characters.”
明确了这些细节后,我开始思考解题方法。由于这个问题涉及到字母匹配和子串查找,我认为使用**Trie(前缀树)**是一个比较合适的选择,因为它擅长处理字符串前缀匹配。
我:
“I think a good way to approach this would be to use a Trie structure to store the dictionary words. That way, as we traverse the swype path, we can quickly look up the possible words that match the path.”
面试官:
“That sounds like a reasonable approach. Can you explain in more detail how you would use the Trie for this problem?”
我:
“Sure. I would first build a Trie from the given word list. Each node in the Trie would represent a character. As we traverse the swype path, we would attempt to match each character in the Trie. If we reach a valid word node, we return that word. If we can't find a match at any point, we backtrack and try the next possible character in the swype path.”
面试官:
“Great! Go ahead and code it.”
于是我开始编写代码。为了便于面试官理解,我首先写了伪代码解释了我的思路:
First Problem: Swipe Path Prediction
The first problem presented was related to Swipe Path prediction.
Problem Statement:
"When someone drags their finger across a phone's keyboard, we can record the letters they intersected, creating a swype path. Given a swype path and a list of words, write a function to guess what the user is trying to type."
Input:
- A string representing the swipe path, e.g.,
"bjiojbfdsaq" - A list of words, e.g.,
["boba", "tea", "apple"]
Output:
- Return the most likely word the user was trying to type, e.g.,
"boba"
Upon hearing the problem, I immediately asked a few clarifying questions to ensure I fully understood the constraints.
Me:
“Are we assuming all letters in the input are lowercase? Also, do we need to consider non-alphabetic characters, or will the input always be valid English words?”
Interviewer:
“Yes, you can assume the input will only contain lowercase English letters, and no need to handle non-alphabetic characters.”
After confirming these details, I began thinking of potential solutions. Given that the problem involved matching letters from a swipe path to possible words, I thought of using a Trie (prefix tree), which is efficient for handling such prefix-based word matching.
Me:
“I think a good approach here would be to use a Trie data structure to store the list of words. As we traverse the swipe path, we can look up possible words in the Trie. This will allow us to efficiently check for matching words.”
Interviewer:
“That sounds like a solid approach. Could you explain in more detail how you would implement the Trie and match the swipe path?”
Me:
“Sure. First, I’d construct a Trie from the list of words. Each node in the Trie would represent a letter, and paths through the Trie would represent complete words. While traversing the swipe path, I’d check each letter in the Trie. If we find a valid word, I’ll return it. If a letter isn’t found, we’ll backtrack and try a different path.”
Interviewer:
“Great! Go ahead and start coding.”
I then started writing the code. Here’s the pseudocode I used to outline my thoughts:

随后我开始实际编写代码,面试官也会时不时插话询问我的思路是否清晰。
面试官:
“So how would you handle multiple matches in this case? For example, if both ‘boba’ and ‘bob’ are possible matches?”
我:
“In that case, I would return the longer word, or if they’re the same length, I would return the lexicographically smaller one.”
面试官:
“Okay, sounds good. Keep going.”
我继续编写代码,最终完成了Trie的构建和路径遍历的逻辑。在测试了一些简单的边界条件后,面试官对此方案表示满意。
总结:
这个问题考察了如何处理字符串匹配,以及如何通过高效的数据结构优化查找过程。使用Trie结构有效地缩短了查找时间,减少了重复计算。
Interviewer:
“How would you handle multiple matches in this case? For example, if both ‘boba’ and ‘bob’ are possible matches?”
Me:
“In that case, I would return the longer word, or if they’re the same length, I would return the lexicographically smaller one.”
Interviewer:
“Okay, sounds good. Continue.”
I completed the code and tested it against some sample inputs. The solution worked as expected, and the interviewer seemed satisfied with the approach.
Solution Reflection:
This problem tested my ability to apply string matching efficiently. Using a Trie allowed for quick lookups and reduced the need for repeated substring comparisons. By using the Trie structure, I could significantly improve the time complexity, especially when dealing with large dictionaries of words.
第二个问题: 消息去重
第二个问题涉及到一个实时数据过滤的任务。
面试官问题原文: "We have a system that sends timestamped messages. However, the hardware is noisy, and sometimes we receive duplicate messages. Write a program to filter out duplicate messages that occur within a 10-second window."
输入:
- 消息格式为
timestamp, message,例如:
10 solar panel activated
9 solar panel activated
20 solar panel activated
期望输出:
10 solar panel activated
20 solar panel activated
面试官给出的这个问题看似简单,但涉及到的细节比较多。我首先确认了输入的格式以及一些处理细节。
我:
“Are the messages guaranteed to be sorted by timestamp, or do I need to handle out-of-order messages as well?”
面试官:
“They are not guaranteed to be sorted, so you'll need to handle that.”
我:
“Got it. Also, do we consider two messages with the same content but different timestamps as duplicates if they occur within the 10-second window?”
面试官:
“Yes, as long as the message content is the same and they fall within that window, they should be considered duplicates.”
在确认了这些细节后,我决定使用**deque(双端队列)**来处理消息的去重问题。deque可以很好地处理固定窗口内的元素管理,同时保证了时间复杂度的高效性。
我:
“My approach would be to use a deque to store messages within the 10-second window. For each new message, I’ll check if it’s already in the deque. If not, I’ll add it to the output and to the deque. If it’s a duplicate, I’ll just discard it.”
面试官:
“That makes sense. Let’s see the code.”
Second Problem: Message Deduplication
The second problem was a real-time data filtering challenge.
Problem Statement:
"We have a system that sends timestamped messages. However, the hardware is noisy, and sometimes we receive duplicate messages. Write a program to filter out duplicate messages that occur within a 10-second window."
Input:
- Messages in the format
timestamp, message, e.g.:
10 solar panel activated
9 solar panel activated
20 solar panel activated
Expected Output:
10 solar panel activated
20 solar panel activated
After hearing the problem, I immediately asked about the nature of the inputs.
Me:
“Are the messages guaranteed to be sorted by timestamp, or do I need to handle out-of-order messages?”
Interviewer:
“They are not guaranteed to be sorted, so you’ll need to handle that.”
Me:
“Got it. Also, should I consider two messages with the same content but different timestamps as duplicates if they fall within the 10-second window?”
Interviewer:
“Yes, as long as the message content is the same and they fall within that window, they should be considered duplicates.”
With these clarifications in mind, I decided to use a deque (double-ended queue) to manage the message window. The deque would hold messages within the 10-second window, and I would compare incoming messages to the ones in the deque to identify duplicates.
Me:
“I’m thinking of using a deque to store messages within the 10-second window. For each new message, I’ll check if it’s already in the deque. If not, I’ll add it to the output and the deque. If it’s a duplicate, I’ll ignore it.”
Interviewer:
“That makes sense. Let’s see the code.”
I proceeded to code the solution and explained my steps:
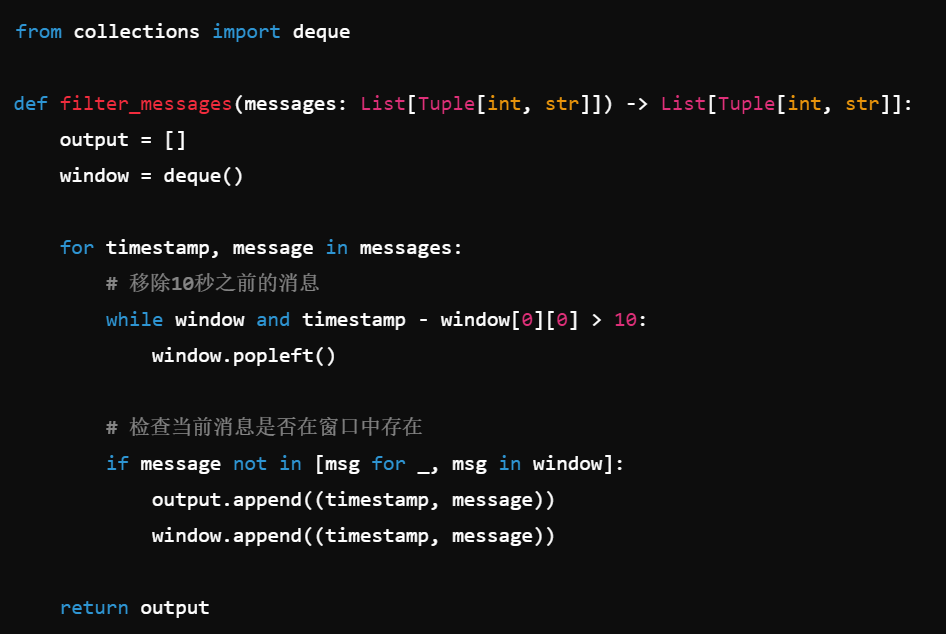
在这段代码中,我使用了deque来维护一个10秒窗口,并实时检查是否有重复消息。
面试官:
“Your approach looks good. What if the messages arrive out of order? How would you adjust for that?”
我:
“I would sort the messages based on their timestamps before processing them. Alternatively, I could modify my deque logic to handle out-of-order timestamps by checking the timestamp of the current message and comparing it with the timestamps of existing messages in the deque.”
我们讨论了一些处理无序消息的思路后,我完善了代码,使其能够应对乱序输入的情况。
面试总结
在整个面试过程中,除了编写代码,沟通也是至关重要的一部分。面试官希望通过对话了解你的思维过程,确保你能够清晰表达自己的想法,并在遇到不确定的地方及时提出问题。我在每个问题开始时都会通过clarifying questions确保自己理解了问题的全部细节,这帮助我避免了很多潜在的陷阱。
这次面试不仅考察了我的编程能力,还非常关注我如何处理问题和在实时压力下调整方案。在面对第一个问题时,我最初采用了Trie的数据结构,但后来根据时间和复杂度的考虑,我切换到了更简单的双指针方案。这个灵活调整方案的能力也得到了面试官的认可。
总的来说,这次面试让我更加深刻地理解了在大型技术公司中,技术能力、思维逻辑和沟通技巧同等重要。
As I wrote the code, the interviewer asked me about handling out-of-order messages.
Interviewer:
“What would you do if the messages arrived out of order?”
Me:
“I could sort the messages by timestamp before processing them, or I could adjust the deque logic to handle out-of-order timestamps by checking if the current message’s timestamp is within the valid window, even if it's out of order.”
After discussing a few adjustments for handling out-of-order messages, I completed the implementation and tested it. The interviewer was pleased with the solution.
Interview Reflection
Throughout the interview, communication was as important as coding. The interviewer was keen to see not just my technical abilities but also how I approached problems, clarified requirements, and adjusted my solutions. By asking clarifying questions at the beginning of each problem, I ensured I had a solid understanding of the task before diving into the code.
The first problem allowed me to demonstrate my knowledge of Trie data structures, but I also showed flexibility by switching to a simpler two-pointer solution when discussing alternative approaches with the interviewer. The second problem challenged me to think about real-time message filtering and consider issues like out-of-order inputs and efficient data handling using a deque.
In conclusion, the interview highlighted the importance of balancing technical skills with problem-solving approaches and clear communication. It’s not just about finding the correct solution but also about explaining the reasoning behind it and showing adaptability when things don’t go as planned.
如果您需要面试辅助或面试代面服务,帮助您进入梦想中的大厂,请随时联系我。
In this Google interview, I demonstrated my understanding of common algorithmic problems and my problem-solving abilities. Each problem presented different challenges, but all could be solved through logical algorithm strategies.
If you need more interview support or interview proxy practice, feel free to contact us. We offer comprehensive interview support services to help you successfully land a job at your dream company.
