Problem: You are asked to implement a document compressor that supports two functions:
encode(A): given a string A (ASCII only), return a binary string A' representing the encoded document.
decode(A'): given the encoded string A', return the original string A.
Compression is based on character frequency: characters that appear more often should be assigned shorter binary codes, while characters that appear less often should be assigned longer codes. The output should be represented as a string of '0' and '1'.
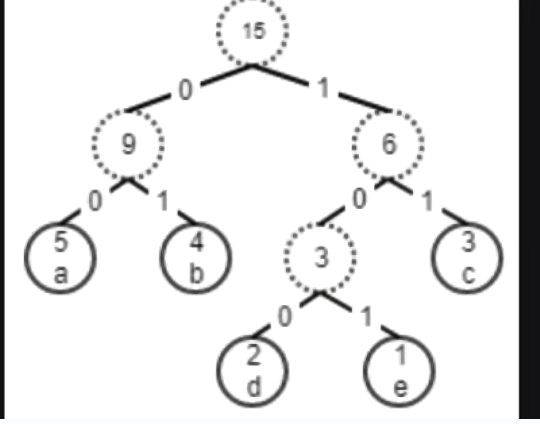
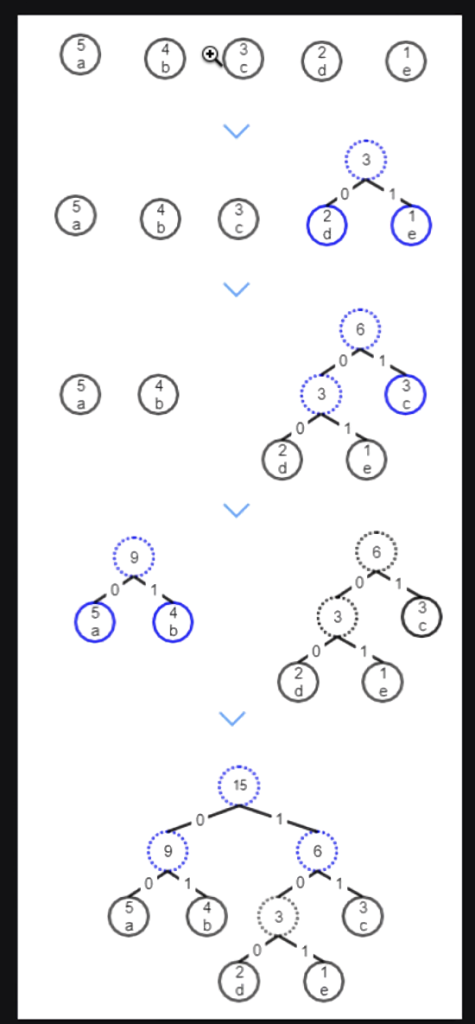
For example, given the string "aaaabbbcccdde", one possible encoding tree is as follows:
After encoding, the string becomes "0000000000010101111111100100101", which is only 33 bits compared to the original 15 * 8 = 120 bits.
To construct a tree like above, you start by pairing the least frequent characters first, then build upwards. There can be multiple valid trees. We aren’t requiring the absolute best compression.
Your implementation is considered good as long as it is:
correct: successfully recovers to the original string A
effective: the compressed string is shorter than the original (len(A') < len(A) * 8).