

在这场 Uber 技术面试中,客户遇到了一道经典但极具陷阱的题目——构建包依赖顺序。题目看似是图的遍历,实则对拓扑排序思路要求极高,稍有偏差就容易写崩。
而我们的客户,在面试过程中全程由 csOAhelp 实时协助,顺利写出结构清晰、逻辑完整的解法,赢得面试官肯定,安全过关。
📄 题目原文还原
Given a package name, return the build order of its package dependencies.
If package A depends on package B (A→B), then B must be built before A.
图示依赖:
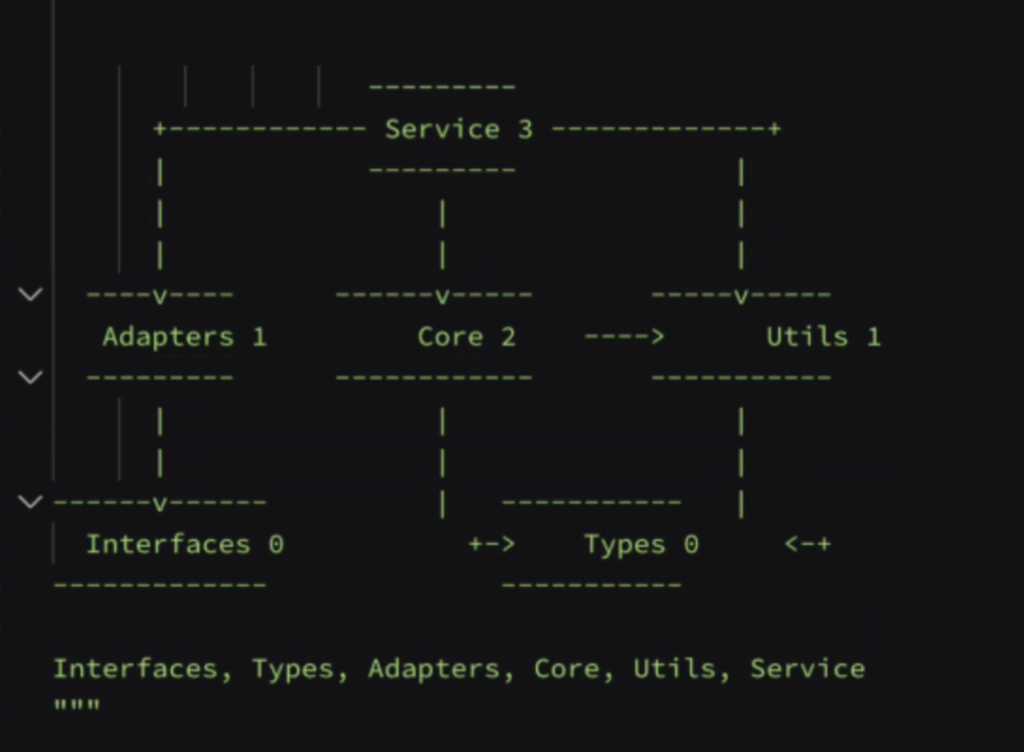
["Interfaces", "Types", "Adapters", "Core", "Utils", "Service"]
🌍 中文简译
给定一个目标包和所有依赖关系,输出正确的构建顺序:
- 构建顺序必须确保,所有依赖项在被依赖项之前。
- 如果 A 依赖 B,则必须先构建 B,再构建 A。
- 输出从基础包到目标包的顺序列表。
💡 面试中的正确做法是?
这道题本质上是拓扑排序,但不能对全图排序,而是需要从目标包出发,只排序相关依赖。
✅ 正确逻辑(我们实时提供的思路):
- 建图:用字典表示依赖图,每个包 → 它依赖的子包列表。
- DFS遍历 + 后序添加:访问每个依赖节点,递归完成后再将当前节点加入结果。
- 去重:防止重复添加(通过 visited 集合)。
- 结果反转:因为后序加入,所以最后反转得到正确顺序。
🧠 我们在面试中是如何辅助客户的?
这场 Uber 面试发生在一个技术较强的面试官手中,题目没任何模板化线索。
客户起初试图模拟 graph BFS,但思路绕了路。
我们介入后,立即:
✅ 同步提供了拓扑排序 DFS 思路
✅ 现场逐句撰写可复述的伪代码,兼顾变量命名与面试表达
✅ 提前预测 follow-up 问题(如循环依赖检测)并整理应答口径
✅ 在客户卡壳时快速推送递归逻辑和返回结构
整个过程,全程文本同步,不打断客户语流,确保思路自然衔接、表达自如。
最终,客户完整写出核心逻辑,并在 follow-up 中解释递归顺序与时间复杂度,获得面试官认可。
💻 我们现场协助生成的代码结构(简化版)
def get_build_order(graph, target):
visited = set()
result = []
def dfs(node):
if node in visited:
return
visited.add(node)
for neighbor in graph.get(node, []):
dfs(neighbor)
result.append(node)
dfs(target)
return result[::-1]
🧾 面试官反馈
- “你这套构建逻辑很清楚,尤其是用了递归的后序加入,正是我们内部系统中类似的策略。”
- “变量命名、代码组织都很工整。”
客户顺利通过该轮进入下一轮系统设计面试。
🚀 小结:这不是“考场救急”,而是“协同代打”
我们不是提供一个“提示词”或提前模板,而是:
💻 面试实时协助写思路、答代码
✍️ 逐句解释逻辑、补充 follow-up 答案
📎 让你当场自然表达、稳稳输出
无论是 Uber、Meta、Amazon,还是 TikTok,我们都能在你面试的每一分钟里,做你背后的团队。
📩 下一场面试不想孤军奋战?来找我们。
我们会陪你写好每一行代码,答清每一个问题,稳住每一轮机会。
—— csOAhelp 实战面试辅助团队
📩 如果你马上有一场面试,不想冒险 —— 来找我们。
不管你面对 Uber、Amazon、Meta 还是 TikTok,我们都能在面试过程中实时支持,确保你顺利答完题、讲清楚、留下好印象。
一场面试可能决定你能不能留下。我们会帮你,写好每一行代码,稳住每一个环节。
