

今天继续聊聊最近热门的Snapchat面试!是不是还在为AI面试摸不着头脑?别慌,今天就来给大家扒一扒Snapchat真实二面场景,手把手教你如何应对那些“烧脑”的算法题,让你轻松通过二面,离Offer更进一步!赶紧收藏起来,变身面试达人!
🌟 二面实录:揭秘Snapchat的硬核算法题
话说,Snapchat的面试流程一向以技术深度著称。这次二面,考官明显想考察候选人对PyTorch框架的深入理解和模型优化能力。题目一上来就直奔主题,就是要你“手撕”一个在PyTorch模型中融合Batch Normalization层(BN)的函数。听起来是不是有点高级?别担心,我们来层层拆解!
🤯 面试官的“灵魂拷问”:融合BN层?
面试官抛出的题目是这样的:
面试题原文:
1. You need to implement a function that fuses batch normalization layers within a PyTorch Sequential module.
2. To be more precise, the objective is to merge each pair of convolution layer and its subsequent batch normalization layer into a single convolution layer.
3. The fused convolution layer should be constructed in such a way that it produces the same results as the original combination of the convolution and batch normalization layers.
Additional details:
- You can access the parameters of the batch normalization layer through the following attributes: eps, weight, bias, running_mean and running_var.
- The parameters for the convolution layer are found in weight.data and bias.data.
- The relevant PyTorch classes are nn.Conv2d for the convolution layer and nn.BatchNorm2d for the batch normalization layer.
Example:
[Conv1, BN1, Activ, Conv2, Conv3, BN3, Activ, Pool] => [Conv1f, Activ, Conv2, Conv3f, Activ, Pool]
简单来说,就是要把卷积层(Conv2d)后面紧跟着的批归一化层(BatchNorm2d)“吸”到卷积层里面去,变成一个融合后的卷积层(Conv_fused),而且效果要和之前一模一样!这是深度学习模型部署和推理优化中非常常见的技巧哦,可以大大减少模型大小和计算量,提升推理速度!
🤔 解题思路大揭秘:数学原理是关键!
在面试过程中,通常会先有几分钟的思考时间。面对这种题,你需要在脑海里快速过一遍BN层的数学原理。
BN层公式:
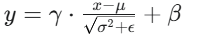
其中,x 是输入,μ 是均值,σ2 是方差,γ 是缩放因子(weight),β 是偏移因子(bias),ϵ 是为了数值稳定的小常数(eps)。1
而卷积层的输出是:
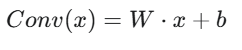
把卷积层的输出代入BN层公式,进行一系列数学推导(这部分是面试中需要向面试官解释的),你就能得到融合后的卷积层新的权重 (Wfused) 和偏置 (bfused) 公式:
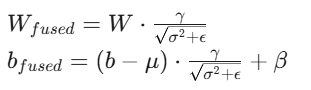
理解了这些,代码实现就水到渠成了!
💻 核心代码思路展示:手把手教你实现!
面试中,考官会让你在屏幕上写代码。通常会给你一个基本的函数签名,你需要填充逻辑。核心思路可以分为两步:
- 实现单个Conv-BN对的融合函数 (
fuse_conv_bn_pair):- 创建一个新的
nn.Conv2d层,它的输入输出通道、卷积核大小、步长、填充等参数都和原始的Conv2d层保持一致。 - 关键一步: 根据前面推导的数学公式,利用原始卷积层的权重 (
conv.weight)、偏置 (conv.bias) 和BN层的参数(bn.running_mean,bn.running_var,bn.weight(即 γ),bn.bias(即 β),bn.eps)来计算新的卷积层权重和新的偏置。 - 将计算出的新权重和偏置赋值给新创建的
nn.Conv2d层的weight.data和bias.data。 - 注意处理原始卷积层没有偏置(
bias)的情况。
- 创建一个新的
- 遍历整个
nn.Sequential模块并融合所有对 (fuse_sequential_model):- 创建一个空的
nn.Sequential作为融合后的模型。 - 遍历原始模型中的所有层。
- 如果当前层是
nn.Conv2d且下一层是nn.BatchNorm2d: 调用第一步实现的fuse_conv_bn_pair函数来融合这两个层,并将融合后的层添加到新的模型中。同时,跳过原始模型中的BN层,因为它已经被融合了。 - 如果当前层是
nn.Sequential(嵌套模块): 递归调用fuse_sequential_model函数来处理这个嵌套的Sequential模块,并将处理后的模块添加到新模型中。 - 如果当前层不是Conv-BN对,也不是嵌套的Sequential: 直接复制该层并添加到新模型中。
- 记得处理循环中最后可能未被处理的层。
- 创建一个空的
代码思路解析:
遍历与构建新模型: 遍历 nn.Sequential 时,要考虑如何跳过已被融合的层,并正确构建新的 Sequential 模型。递归处理嵌套的 Sequential 模块也体现了代码的通用性。
数学推导是核心: 理解BN层如何被“吸”入卷积层,并推导出新的权重和偏置公式是解决问题的关键。
参数操作: PyTorch模型的参数通常通过 .weight.data 和 .bias.data 访问和修改。
广播机制: 在调整权重时,需要注意BN层的参数通常是 [out_channels] 形状的,而卷积层权重是 [out_channels, in_channels, kernel_h, kernel_w] 形状的,需要利用PyTorch的广播机制进行正确乘法(例如通过 .reshape([-1, 1, 1, 1]))。
💡 面试技巧:除了代码,你还能展示啥?
- 沟通交流是王道! 在写代码前,先和面试官确认思路,比如是否可以使用
torch库,递归处理嵌套模块的策略等等。面试不是考你写代码速度,而是考你的思维过程和沟通能力。 - 考虑边缘情况! 比如卷积层是否有偏置(bias)?BN层参数的维度如何与卷积层参数进行广播(broadcasting)操作?这些细节都会体现你的严谨性。
- 解释你的代码! 写完代码后,要清晰地向面试官解释每一步的逻辑,以及为什么这样实现。特别是数学推导部分,要讲清楚。
- 讨论实际应用! 如果时间允许,可以主动提及这个技术在实际项目中的应用场景,例如模型压缩、量化、推理加速等,这能体现你对深度学习工程实践的理解。
🔥 Snapchat面试Tips:知己知彼,百战不殆!
根据真实面试经历和Snapchat的招聘特点,以下是为你总结的面试攻略:
- 技术深度与广度兼备: Snapchat作为一家前沿的科技公司,对候选人的技术要求非常高。除了扎实的算法和数据结构基础,对于深度学习框架(PyTorch/TensorFlow)、模型优化、分布式系统等领域的理解也至关重要。
- 代码实现能力: 远程面试通常会要求实时编码,代码的清晰度、健壮性、效率都是考量标准。平时多刷LeetCode,更要注重实践项目中代码质量的提升。
- 解决问题能力: 面试官往往会抛出开放性问题或有一定难度的题目,考察你分析问题、拆解问题、逐步解决问题的能力。遇到难题时,不要慌张,可以尝试将大问题分解为小问题,并与面试官进行沟通。
- 沟通表达能力: 面试过程中,清晰、有条理地表达自己的思路和解决方案,与面试官积极互动,是成功的关键。
- 对Snapchat的理解: 了解公司的产品、技术栈、文化,并在面试中适时提及,能让面试官感受到你的诚意和热情。
经过csoahelp的面试辅助,候选人获取了良好的面试表现。如果您需要面试辅助或面试代面服务,帮助您进入梦想中的大厂,请随时联系我。
If you need more interview support or interview proxy practice, feel free to contact us. We offer comprehensive interview support services to help you successfully land a job at your dream company.
