

Java 面试经验分享
面试背景
面试公司是一家社交媒体公司,目标是识别其平台上的顶级影响者。公司定义了一个影响者,是那些具有高覆盖率和大量有意义互动的用户。面试过程中需要设计一个算法来计算每个用户的“影响分数”,并根据他们的连接和互动找出顶级影响者。
面试过程
一、问题陈述
面试官先给了候选人一个问题陈述:
我们希望设计一个算法来识别平台上的顶级影响者。输入包括三个部分:
- 用户之间的连接列表,表示为用户ID的配对。
- 用户的互动列表,包括点赞、评论和分享。
- 整数K,表示要识别的顶级影响者的数量。
需要编写一个函数,返回基于影响分数的前K个影响者。影响分数应使用以下公式计算:
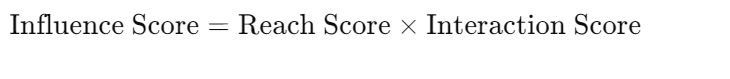
- 覆盖分数:通过连接可以从用户达到的用户数。
- 互动分数:所有入边的权重之和。
Problem Statement
A social media company wants to identify the top influencers on its platform. The company defines an influencer as a user who has a high reach and a significant number of meaningful interactions. To find the top influencers, you need to design an algorithm to compute the "influence score" of each user based on their connections and interactions.
You are given three inputs:
- A list of users' connections (friends), represented as pairs of user IDs.
- A list of users' interactions, which includes likes, comments, and shares.
- An integer K, representing the number of top influencers to be identified.
Write a function that returns the top K influencers based on their influence score. The influence score should be calculated using the following formula:
Influence Score=Reach Score×Interaction Score\text{Influence Score} = \text{Reach Score} \times \text{Interaction Score}Influence Score=Reach Score×Interaction Score
- Reach Score: The number of users that can be reached from the user through connections.
- Interaction Score: The sum of weights of all incoming edges.
Input:
k(1 <= k <= 1000): An integer representing the number of top influencers to identify.connections: A list of tuples, where each tuple(user_id1, user_id2)represents a connection (directed) between two users.interactions: A list of tuples, where each tuple(user_id1, user_id2, weight)represents an interaction (directed) between two users. Weight can be positive (like, share, comment) or negative (dislike). (-1000 <= weight <= 1000)
Output:
- A list of integers representing the top K influencers sorted in decreasing order of influence score.
Example 1
In this example, we have the following Reach and Interaction Scores:
- User 1: Reach Score = 5 (can reach users 2, 3, 4, 5, 6), Interaction Score = 15 (7 from user 4, 8 from user 5)
- User 2: Reach Score = 4 (can reach users 3, 4, 5, 6), Interaction Score = 5 (5 from user 1)
- User 3: Reach Score = 2 (can reach users 4, 5), Interaction Score = 12 (10 from user 2, 2 from user 6)
- User 4: Reach Score = 1 (can reach users 5), Interaction Score = 5 (5 from user 3)
- User 5: Reach Score = 0 (can reach no users), Interaction Score = 3 (3 from user 4)
- User 6: Reach Score = 3 (can reach users 3, 4, 5), Interaction Score = 6 (6 from user 2)
Now, we compute the Influence Scores:
- User 1: Influence Score = 5 * 15 = 75
- User 2: Influence Score = 4 * 5 = 20
- User 3: Influence Score = 2 * 12 = 24
- User 4: Influence Score = 1 * 5 = 5
- User 5: Influence Score = 0 * 3 = 0
- User 6: Influence Score = 3 * 6 = 18
Thus, the top 3 influencers are users 1, 3, and 2, with influence scores of 75, 24, and 20, respectively.
Example 2
Input:
k = 1connections = [(1, 2), (2, 3), (3, 1)]interactions = [(1, 2, 5), (2, 3, 4), (3, 1, 3)]
Explanation:
In this example, we have the following Reach and Interaction Scores:
- User 1: Reach Score = 2 (can reach users 2, 3), Interaction Score = 3 (3 from user 3)
- User 2: Reach Score = 2 (can reach users 1, 3), Interaction Score = 5 (5 from user 1)
- User 3: Reach Score = 2 (can reach users 1, 2), Interaction Score = 4 (4 from user 2)
Now, we compute the Influence Scores:
- User 1: Influence Score = 2 * 3 = 6
- User 2: Influence Score = 2 * 5 = 10
- User 3: Influence Score = 2 * 4 = 8
二、明确需求
为了确保理解准确,候选人向面试官确认了几个问题:
- 影响者类:
- 问:我们需要写一个类来表示影响者吗?
- 答:可以假设已经存在一个包含覆盖分数和互动分数字段的Influencer类。
- 用户表示:
- 问:我们可以假设用户用整数表示吗?
- 答:可以。
- 连接的方向性:
- 问:确认这是有向图吗?
- 答:是的。
三、算法设计
我提出了使用优先队列(最小堆)来解决这个问题的思路:
- 遍历每个影响者,计算其影响分数。
- 如果堆的大小小于K,则将影响者添加到堆中。
- 如果堆的大小已经等于K,则比较新的影响者与当前堆中影响分数最低的影响者,如果新影响者的分数更高,则更新堆。
- 最后从堆中移除K次最小值,并反转输出顺序,得到结果。
面试过程充满挑战,但经过我们的面试辅助服务后,候选人详细的需求确认和一步步的算法设计,最终成功地完成了任务。希望这个经验分享对大家有所帮助!
更多面试真题,面试辅导,面试辅助,代面试等服务,请联系我们。
